

Stop Making AI Read Faster. Make It Read Smarter.
How a 26-year-old MIT PhD student might have just solved AI’s most stubborn scaling problem not with bigger models, but with a 50-year-old computer science trick.

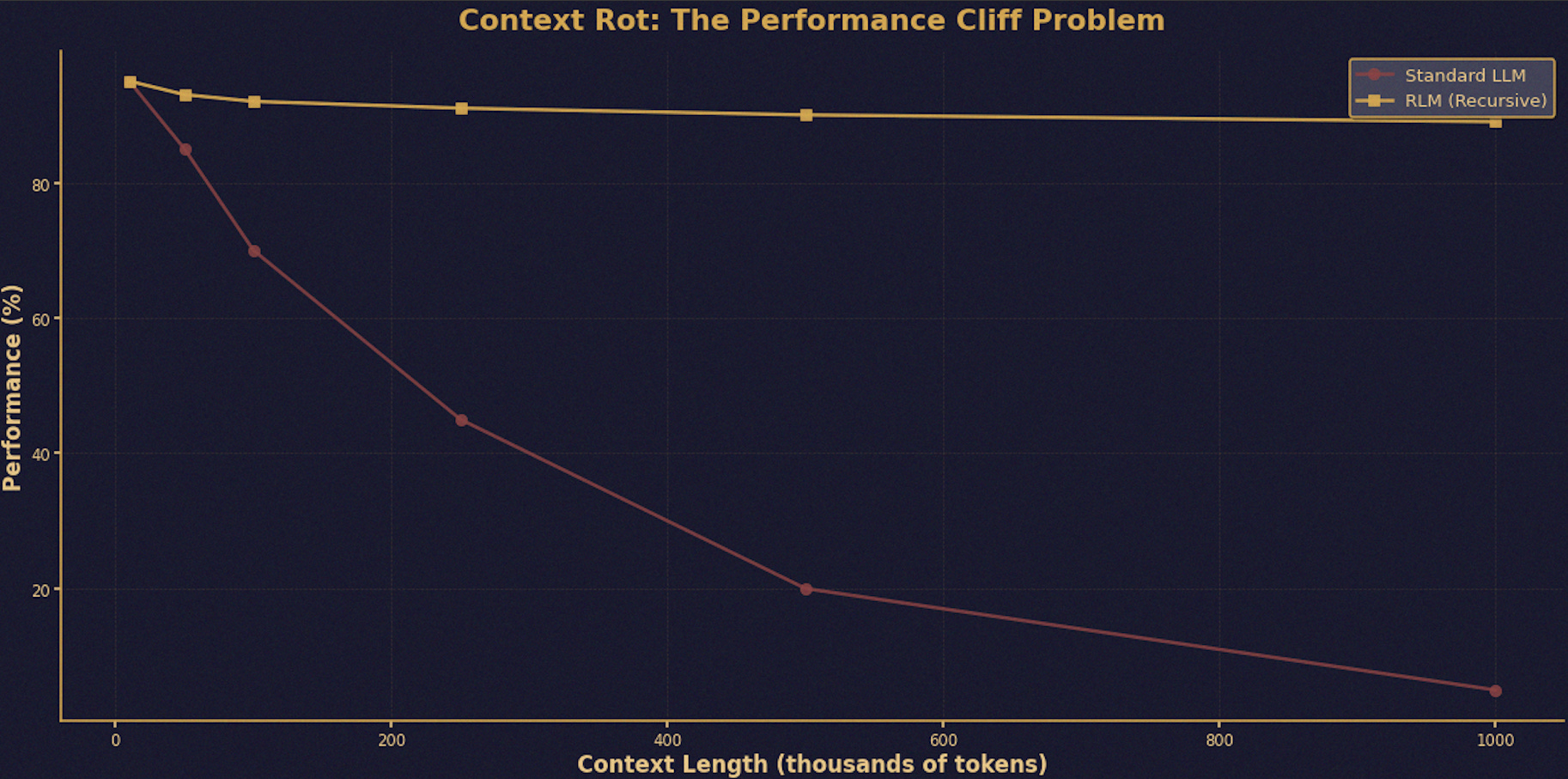
Here’s a number that should bother you: 0%.
That’s the score GPT-5 the most powerful language model on the planet gets when you hand it 10 million tokens of text and ask it to find something specific. Zero. Not “pretty bad.” Not “room for improvement.” Zero.
Now here’s another number: 91.33%. That’s what the exact same model scores on the exact same task …
