

Alice's Brother Has Five Sisters. AI Says Four.
The first comprehensive map of LLM reasoning failures reveals three systematic patterns across 400+ papers and a roadmap for building AI that actually thinks.

Here's a question my six-year-old nephew nailed on the first try:
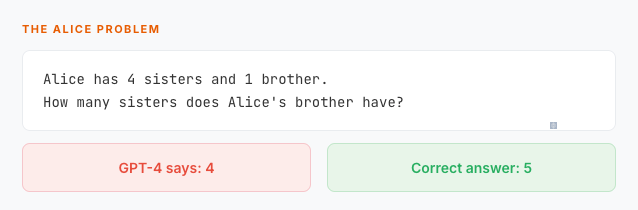
The answer is five. Alice herself is a sister to her brother. A child sees this instantly. GPT-4—the model trusted with legal analysis, medical triage, and billion-dollar code reviews—gets it wrong.
This isn’t a cherry-picked gotcha. It’s one specimen in a vast, now-cataloged ecosystem of r…
